在 LLM(大语言模型)应用开发中,RAG (Retrieval-Augmented Generation,检索增强生成) 已经成为解决模型“幻觉”和“知识过时”问题的标准范式。本文将结合我们的实战项目经验,深入探讨如何构建一个生产可用的企业级 RAG 系统。
为什么需要 RAG?
ChatGPT 等通用大模型虽然知识渊博,但它们主要面临两个核心局限:
- 知识截止:模型训练数据有截止时间,无法通过训练获知最新的新闻或数据。
- 私有数据缺失:模型不知道你公司的内部文档、代码库或客户资料。
RAG 通过“外挂大脑”的方式解决了这个问题:先去知识库里“搜索”相关片段,再把片段作为“参考资料”喂给 AI,让 AI 基于参考资料回答问题。
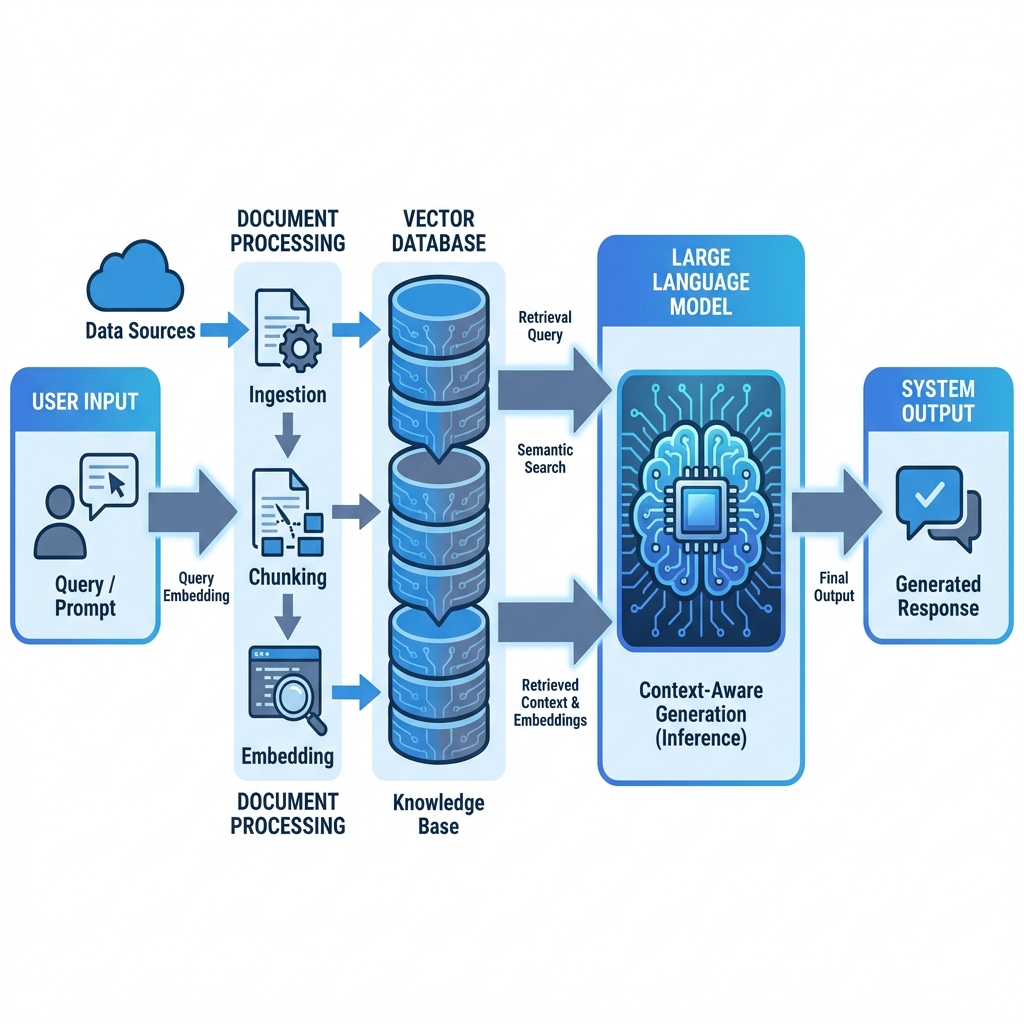
典型的 RAG 数据处理流程:加载 -> 切分 -> 嵌入 -> 存储 -> 检索 -> 生成
技术选型架构
在我们的 OA 基管家项目中,我们采用了以下技术栈:
- Framework: LangChain (Python)
- Vector DB: ChromaDB (轻量,适合部署)
- Embedding: OpenAI text-embedding-3-small (性价比高)
- LLM: GPT-4o / DeepSeek V3
核心实现步骤
1. 文档加载与切分 (Chunking)
文档切分是 RAG 质量的基石。切分太粗,包含太多无关噪声;切分太细,丢失上下文完整性。我们推荐使用 RecursiveCharacterTextSplitter。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个片段约 500 字符
chunk_overlap=50, # 重叠 50 字符,保证上下文连贯
separators=["\n\n", "\n", "。", "!", "?"] # 优先按段落切分
)
docs = text_splitter.split_documents(raw_documents)2. 混合检索 (Hybrid Search)
纯向量检索(Dense Retrieval)擅长语义匹配,但对专有名词(如项目代号 "Project Alpha")匹配能力较弱。关键词检索(Keyword Search, BM25)则恰好相反。
生产环境建议使用 EnsembleRetriever 结合两者:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
# 1. 关键词检索器
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 5
# 2. 向量检索器
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# 3. 混合检索器 (权重 50/50)
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5]
)进阶优化技巧
为了进一步提升实战效果,我们还在系统中引入了:
- Re-ranking (重排序): 使用 Cohere Rerank 模型对初步检索回来的 20 条结果进行精细打分,取前 5 条给 LLM。
- Multi-Query (多路查询): 让 LLM 把用户的一个问题改写成 3 个不同角度的问题并行搜索,提高召回率。